
Aprendizado de Máquinas
“Aprendizado de Máquinas é o campo de estudo que fornece aos computadores a habilidade de aprender sem serem programados explicitamente [para tal].”
Atribui-se que a definição de Aprendizado de Máquinas (AM) foi cunhada por Arthur Samuel em um artigo de 1959[1]. Sendo, na verdade, interpretação do estudo publicado, o autor afirma de fato em seu texto que “os estudos relatados se preocuparam com a programação de um computador digital para agir de forma que, se realizada por seres humanos ou animais, seria descrita como envolvendo o processo de aprendizagem. […] Programar computadores para aprender a partir da experiência deve eventualmente eliminar a necessidade de muito do esforço de programação detalhada.” Mais ainda, “esses esquemas de aprendizagem poderão eventualmente ser economicamente viáveis quando aplicados a problemas da vida real.”.
Ramo específico da Inteligência Artificial (IA), que é capaz de reproduzir habilidades humanas de raciocinar e aprender, o AM analisa dados, treinando máquinas para automatizar a construção de modelos analíticos, identificação de padrões e tomada de decisões, aprendendo de forma iterativa com as informações que lhes são fornecidas.
O AM tem ganhado cada vez mais impulso, sendo reconhecido como tecnologia com alto potencial de lidar bem com o cenário do Big Data, fornecendo intuições valiosas, muitas vezes em tempo mínimo ou até mesmo em tempo real, capazes de garantir a eficiência de atividades que podem significar o diferencial competitivo de uma organização.
Abordagens
Embora com o objetivo comum de extrair informações, padrões e relações úteis na tomada de decisões, há algumas abordagens diferentes de AM. Os computadores aprendem com os dados por meio de métodos iterativos e se tornam capazes de automatizar o processo de aprendizagem e de examinar a estrutura dos dados, ainda que não esta seja conhecida pelo pesquisador.
Quando há um conjunto de dados com certa classificação ou rotulagem estabelecida, isto é, quando existe a possibilidade de treinar um algoritmo por meio de exemplos de entrada cuja saída é conhecida, tem-se o chamado aprendizado supervisionado, capaz comparar e classificar dados, encontrar padrões para identificar especificidades em imagens, por exemplo, além de fornecer previsões para valores de rótulos em dados não rotulados adicionais.
Na situação em que os dados são não rotulados, ou seja, uma “resposta” não é informada ao sistema e este deve entender e analisar as informações, encontrando uma estrutura e classificando os dados com base nos padrões e associações obtidos, o chamado aprendizado não supervisionado é utilizado, por exemplo, para identificar grupos de clientes com características em comum para recomendar itens e serviços ou identificar discrepâncias.
Por sua vez, há o chamado aprendizado semissupervisionado, utilizado para as mesmas aplicações que o aprendizado supervisionado, porém manipulando tanto dados rotulados quanto não rotulados em métodos como classificação, regressão e previsão. Em geral, essa abordagem é útil quando o custo associado à rotulação é muito alto para possibilitar um processo de treinamento totalmente rotulado, como a identificação facial em uma webcam, por exemplo.
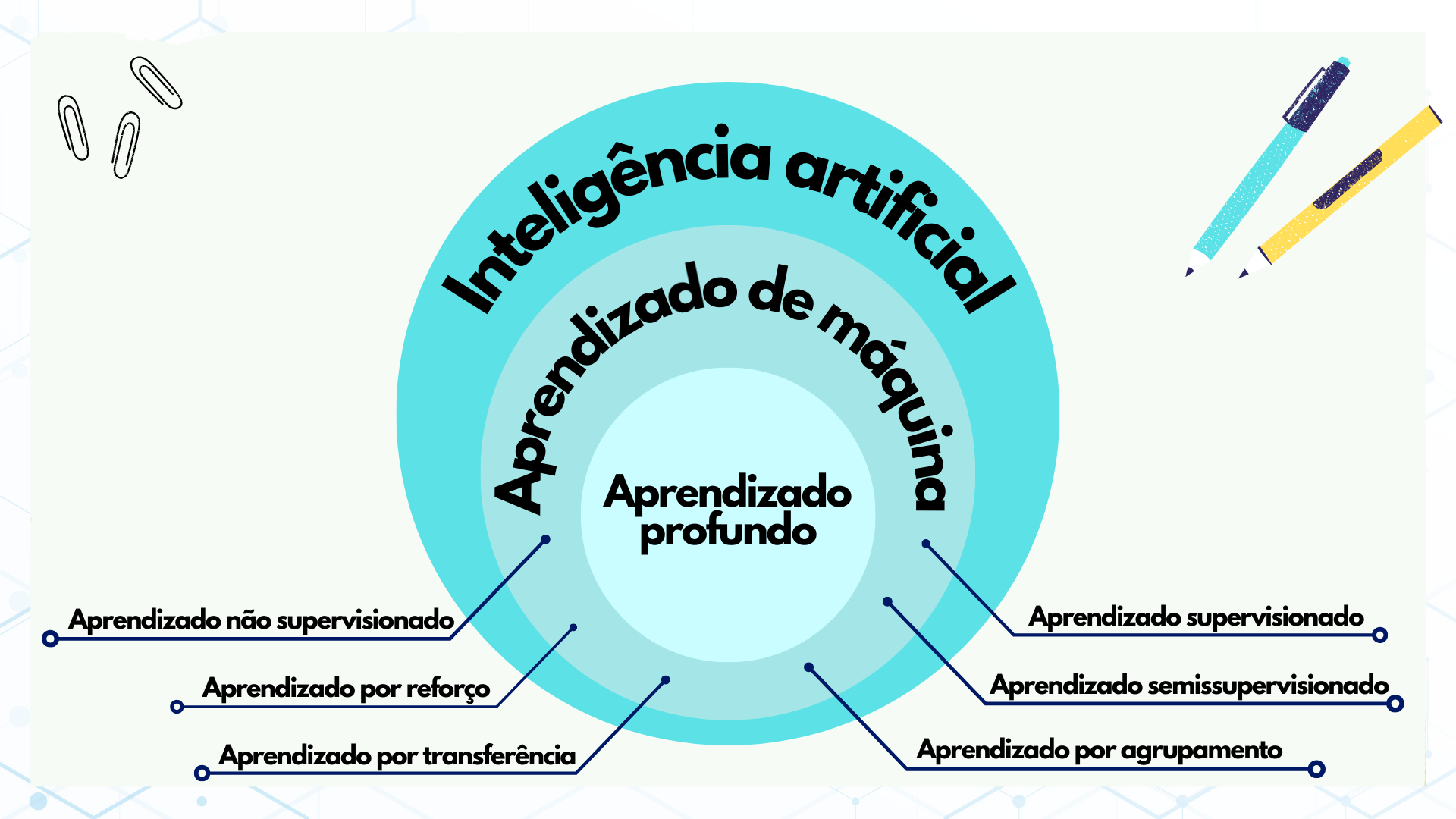
Aprendendo por meio de tentativa e erro, o chamado aprendizado por reforço tem como objetivo maximizar o resultado esperado por meio de uma sequência de decisões que, se bem-sucedidas, resultará no reforço do processo à medida que melhora a resolução do problema em questão.
Com o intuito de aprimorar a aprendizagem por meio do reuso do conhecimento já adquirido em um modelo anterior, o chamado aprendizado por transferência reduz o tempo gasto com o treinamento de grandes modelos e ajuda a suprir a falta de grandes conjuntos de dados para treinamento, sendo bastante útil em aplicações de identificação de padrões ou classificação de imagens.
A estratégia de construir um modelo de aprendizado mais complexo e robusto por meio da combinação de uma coleção de modelos mais simples, minimizando suas desvantagens individuais e aliando seus pontos fortes, define o aprendizado por agrupamento, bastante efetivo, por exemplo, em problemas de predição, classificação e regressão.
O método específico que incorpora redes neurais — projetadas para mimetizar o funcionamento do cérebro humano — em camadas sucessivas para aprender com os dados de uma maneira iterativa é chamado de aprendizado profundo, cujas aplicações por meio das redes neurais profundas às demais formas de aprendizagem são ativamente utilizadas e pesquisadas. O aprendizado profundo é especialmente útil para aprender padrões de dados não estruturados, em aplicações tais como reconhecimento de padrões em sons, fala e imagens para diagnósticos médicos, por exemplo.
Aprendizado de Máquinas na Visibilia
A Visibilia oferece aos seus clientes e parceiros uma variedade de maneiras de aproveitar os benefícios do Aprendizado de Máquinas, por meio de aplicações que podem ser utilizadas via mobile, localmente ou em nuvem. Disponibilizando soluções prontas ou à medida, nossos serviços são orientados para que os usuários tenham ao alcance ferramentas confiáveis ou suporte técnico-científico para obter os melhores resultados e resolver os mais variados desafios.
Entre em contato e saiba mais sobre as diferentes maneiras nas quais a Visibilia pode ajudar você e sua empresa: https://visibilia.net.br/empresa#contato
Referências:
[1] A. L. Samuel, “Some Studies in Machine Learning Using the Game of Checkers,” em IBM Journal of Research and Development, vol. 3, no. 3, pp. 210-229, July 1959, doi: 10.1147/rd.33.0210.
Hastie, T., Tibshirani, R., & Friedman, J. (2009). The elements of statistical learning: data mining, inference, and prediction. Springer Science & Business Media.
Müller, A. C., & Guido, S. (2016). Introduction to machine learning with Python: a guide for data scientists. O’Reilly Media, Inc.
Sarkar, D., Bali, R., & Ghosh, T. (2018). Hands-On Transfer Learning with Python: Implement advanced deep learning and neural network models using TensorFlow and Keras. Packt Publishing Ltd.
Gostou? Compartilhe esse conteúdo: